In the first part about agile estimation, we explained the fundamental principles of the estimation. Now it is time to think about how to implement them in real life.
Reference stories
For estimation, we will need to have ‘the catalog of references‘ so we can compare all new requirements fast & accurately enough. In our first post, we did that with the first few buildings and then compared all the others to those references.

Our catalog should not be specified based on technology – we will not have 1 simple database table, or 1 simple API, or 1 form, or 1 test case in it. The reference catalog must contain valuable functionality.
If a product is a front-end app, the functionality should include data storage, backend, validation, form, an update of manual, tests. Functionality must be working and usable for the client. Similar conditions can be specified even the product is Saas, or mobile application, etc.
Examples of reference stories:
- Small edit form with 5 fields
- Simple text-based filtering
- Import data with up to 10 fields
- Workflow with up to 5 simple steps.
How to deal with different types of requirements?
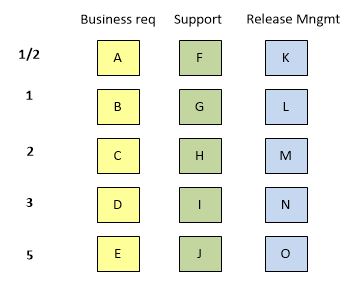
New agile teams are many times multi-disciplined for the first time. Team members do not know what exactly it means to develop requirements. Very often you hear “I know nothing about development, I’m a support guy!” In such a case create a reference catalog with different types of requirements, but distribute them with the same values.
Because of these differences, we should forget “agile” estimation a little bit. Not ideal, I know, but the following steps helped dozens of teams. In such a case create a reference catalog with different types of requirements, but distribute them with the same values.
In the case of different types of requirements, we have to create a reference catalog that supports proper scale configuration.
Later, after a few sprints, you will know how much time you spent on the implementation of requirements. Time is used just for the comparison of requirements of different types so the scale can be aligned more accurately.
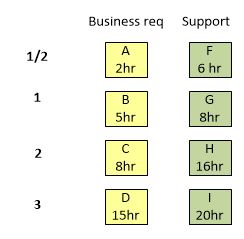
Based on the time spent now you can align the scale accordingly by comparison of the real spent time value.
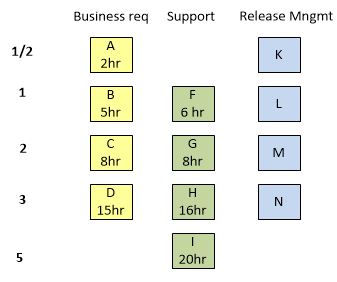
I suggest updating the scale after a few sprints. It must be done based on already completed stories, not based on the estimation of time before such a story is completed! And, don’t care a lot about the velocity chart before such alignment.
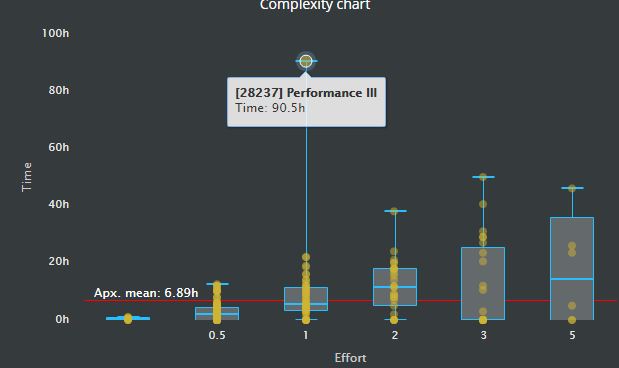
ScrumDesk helps teams to define such scale much faster with help of a Complexity chart.
Estimation groups
What we want to achieve by all these steps is to define groups into which new requirements can be slotted fast & accurately enough. Team members will just compare requirements to requirements in the group. In many teams, we were able to estimate more than 50 requirements just in 1 hour. And accurately, of course!
Typical mistakes
- The catalog is created not together as a team, but by roles.
- The catalog is based on time, not requirements complexity.
- The Catalog values are aligned based on the estimated time, not spent time measured once a story is completed.
- Values are very precise. The goal should be to create groups of requirements.
- The catalog is not created by team members, but some PMO, project management or managerial roles “to align catalog”.
- The catalog is not “discovered”, but defined upfront.
- The catalog is not maintained over time. The values are in practice typically updated once per year.
- Values of the scale are not Fibonacci numbers. The team adds more value than necessary.